超35000+企业的信赖,遍布全球36个国家和地区


















超35000+企业的信赖,遍布全球36个国家和地区
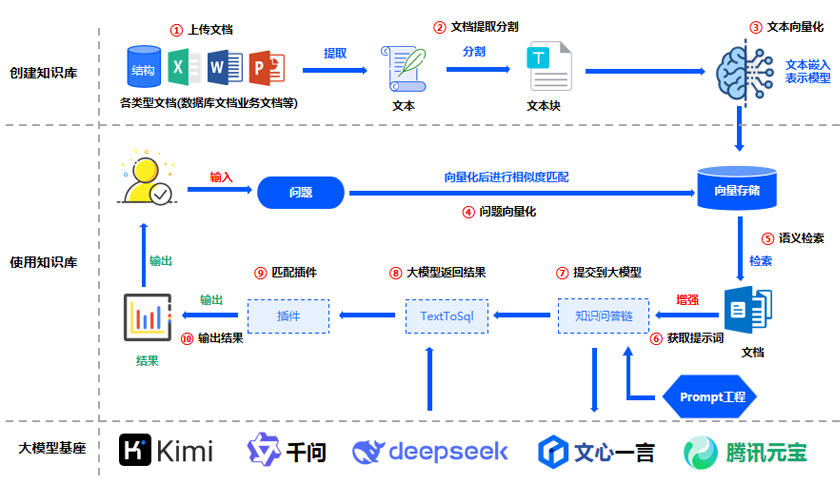
基于企业私有语料与历史数据,进行持续预训练与微调,训练可执行特定任务的AI智能体。
隐性知识显性化并挖掘关联关系,形成可查询、可推理的知识网络与知识复用推广,减少重复劳动。
通过智能生成类任务(文件生成与量化解读等)和合规性审查类任务(法务稽核、校对),实现业务效率提升。
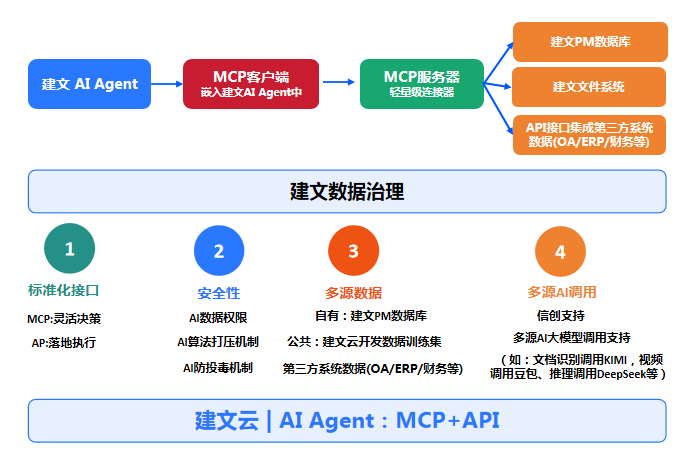
内置API与MCP接口,可对接第三方的ERP、BIM、OA、财务系统等,自动清洗、关联数据,实现多源数据整合。
政企业专属训练:基于企业私有语料与历史数据(如:制度体系、投标资料、竣工资料、预算造价资料、企业内部定额资料等),进行持续预训练与微调,沉淀术语词典、同义词库、审查清单、各类价格模板库等;训练可执行特定任务的AI智能体。
动态学习能力:智能体持续吸收新数据(如政策更新、新材料参数、其他ERP、OA、财务系统数据),自动优化决策逻辑,适应不同项目需求。
免费试用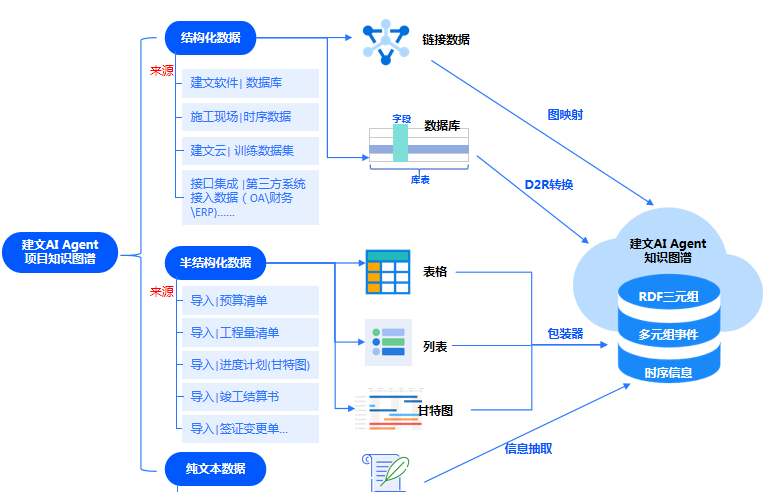
隐性知识显性化:将散落在文档、日志、会议记录、周月报中的工程经验提取为结构化知识节点。
关联关系挖掘:自动建立知识间的关联,形成可查询、可推理的知识网络。
知识复用推广:新项目启动时,智能推荐历史相似项目的成功经验,减少重复劳动。
免费试用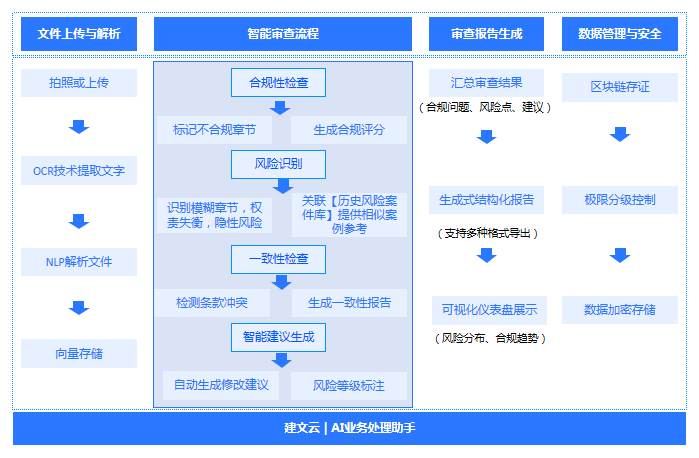
智能生成类任务:依据工程量清单/进度WBS自动生成质量安全风险点、质量目标、安全目标、成本风险点与检查点清单;支持文件翻译、量化解读、总结、量化分析,将复杂文本转化为清晰结论。
合规性审查类: 对手续、合同、制度、对外函件进行要件完整性、流程适配性、权限匹配性审查,标注风险等级与整改建议,前置防控合规与经营风险;
免费试用
多源数据整合:内置API接口,支持MCP协议;MCP 负责 “灵活决策”,API 负责 “高效执行”;自动清洗、关联数据,并自我学习与训练,API+MCP,不再让AI“与世隔绝”。
数据质量监控:识别异常值、重复数据、缺失数据,并生成修正报告。
免费试用核心区别在于:一个是“懂行的专家”,一个是“博学的通才”。
通用大模型: 像一个知识渊博的大学生,懂得很多通用知识,但不懂你们企业的“行话”、内部流程和特定的管理风格。
建文训练后的AI: 像一个在你们企业工作多年的老员工。
懂术语: 它学习了你们的制度体系、历史标书、竣工资料,建立了专属的术语词典和同义词库(例如知道公司内部说的“那个活”具体指哪个分部分项工程)。
懂逻辑: 它沉淀了你们的审查清单和价格模板库,能按照你们企业的标准逻辑去思考和执行任务,而不是给出一个通用的、需要二次加工的答案。
完全可以。 这正是建文AI进行“专属训练”的强项。
制度融合: AI不仅仅是对照国家法律,它会将你公司的合同管理制度、审批权限表、标准合同范本作为核心审查依据。
智能比对: 在进行法务稽核时,AI会自动将合同条款与公司制度进行比对。例如,如果合同金额超过了某一级别的审批权限,或者付款比例偏离了公司标准范本,AI会自动识别并标注为风险点。
合规性审查覆盖了从手续到文本的多个维度,主要包含以下具体应用:
要件完整性审查: 检查文件是否缺页、缺章、缺附件(如检查报建手续是否齐全)。
流程适配性审查: 检查审批流程是否符合规定(如该走“重大合同流程”还是“一般合同流程”)。
权限匹配性审查: 检查签署人是否有权签署该金额或该类型的合同。
条款合规性审查: 自动识别合同或函件中的霸王条款、模糊条款,并标注风险等级(高、中、低)。
能,建议在训练后。基于知识图谱和智能生成能力,AI可以成为编制工作的得力助手。
质量安全文件: 输入工程量清单或WBS(工作分解结构),AI可以自动生成对应的质量安全风险点清单、检查点计划、应急预案要点等。它能自动识别高风险工序并生成防控措施。
标书编制:
素材调用: AI可以自动从历史标书库、企业资质库中提取合适的资质文件、业绩证明、人员证书等。
方案生成: 结合项目特征,AI能辅助生成施工组织设计、技术方案大纲,甚至自动完成部分通用章节的撰写,大幅缩短标书制作周期。
除了上述的标书和质量安全文件,AI还能辅助完成以下“智能编制”类任务:
智能翻译与解读: 对外文合同或技术规范进行翻译,并同步生成关键条款的量化解读和摘要。
会议纪要与报告生成: 将冗长的会议录音或记录,自动整理成结构化的会议纪要,并提炼出待办事项。
公文与函件起草: 根据业务场景(如催款函、联系单),自动生成规范的文本初稿。
数据清洗与整理: 自动将杂乱的数据整理成标准的报表格式。
可以。 建文AI业务助手具备良好的开放性和集成能力。
接口支持: 系统内置了API接口和MCP协议接口。
跨系统调用: 这意味着ERP、BIM、OA、财务系统等其他平台,都可以通过接口调用建文AI的能力。
举例: 当你在OA系统中发起一个审批流程时,OA系统可以调用建文AI的接口,让AI在后台自动完成合规性审查,并将审查结果(如风险点标注)回传给OA系统展示给你看。
不一定。AI的训练并不绝对要求部署私有化大模型,但在企业级应用中,是否选择私有化部署取决于你的数据敏感性、定制化需求以及合规要求。
基础功能:建文AI Agent作为建文产品的配套模块,不单独收费,用户可免费使用。
为了帮你理清这两者的区别,我们可以把“AI训练”和“模型部署”看作两个可以组合的选项。我为你详细拆解一下:
不需要私有化大模型的情况(使用公有云API)
如果你的需求属于通用型,或者处于初期探索阶段,可以直接使用公有云的大模型API(如GPT、文心一言、千问等)。
适用场景:
通用能力辅助: 比如只需要AI帮忙润色邮件、写通用的文案、做简单的翻译,公有模型已经非常强大。
数据不敏感: 处理的内容不涉及公司核心机密、客户隐私或财务数据。
成本敏感(初期): 不想投入高昂的硬件采购成本,按调用次数付费,试错成本低。
局限性:
数据安全风险: 你的数据需要上传到第三方服务器,可能存在泄露风险。
“幻觉”与不稳定性: 通用模型可能不懂你们行业的“行话”,回答可能不够精准,甚至一本正经地胡说八道。
合规红线: 对于金融、政务、大型国企,数据出境或上传至公有云可能违反《数据安全法》或内部审计要求。
需要私有化大模型的情况(本地/专有云部署)
如果你想让AI真正成为企业的核心生产力工具(如建文AI助手的日常业务处理功能:处理合同、成本、合规审查),私有化部署通常是必要的。
为什么必须私有化?
数据安全与合规(核心原因): 建文AI需要学习企业的制度体系、历史标书、成本数据、合同文本。这些属于核心商业机密。私有化部署能确保数据“不出域”,完全掌握在自己手中,满足等保和合规审计要求。
深度定制与微调: 通用大模型不懂“鲁班奖申报流程”或你公司的特定“预算定额”。私有化部署允许你基于企业私有语料对模型进行持续预训练(Continual Pre-training)和微调(Fine-tuning),让AI变成懂你公司业务的“专家”。
业务连续性与低延迟: 依赖公有云API可能会遇到网络延迟或服务中断。私有化部署在本地服务器,响应速度更快(尤其适合高频的报表查询),且不受外部网络波动影响。
知识资产沉淀: 只有私有化模型,才能将企业散落的知识(如老师傅的经验、历史项目的教训)固化下来,形成企业独有的知识图谱和数字资产。